The goal of my research is to advance the field of Large-Scale Optimization. My group provides actionable insights from the perspective of this foundational field to innovate multiple domains including Machine Learning, Deep Learning, Online Learning, Learning in Games, and Networked/Distributed Decision-Making. In doing so, our group designs efficient algorithms with mathematical guarantees to render practical deployment of learning-based systems possible under a variety of considerations such as limited resources, robustness, and adversarial behaviors. Recent applications include Federated Learning, Medical Image Analysis, NextG Manufacturing, and Cyber-Physical Systems. A sample of recent and ongoing projects include:
Online Learning in Dynamic Games
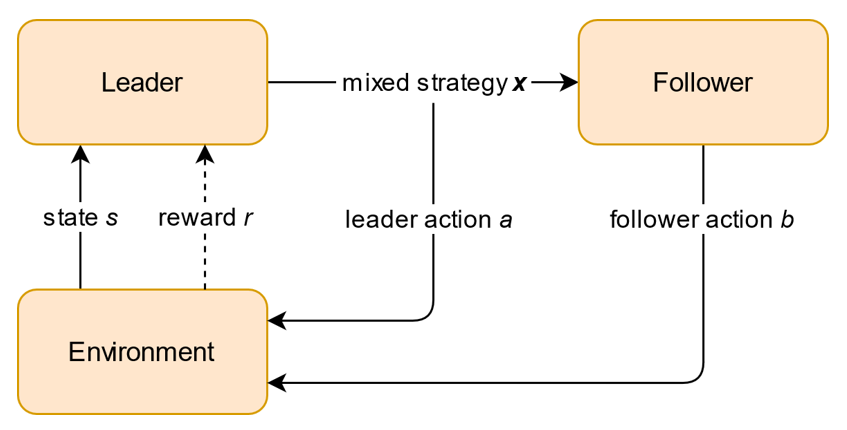
In a Stackelberg game, a leader commits to a randomized strategy, and a follower chooses their best strategy in response. We consider an extension of a standard Stackelberg game, called a discrete-time dynamic Stackelberg game, that has an underlying state space that affects the leader’s rewards and available strategies and evolves in a Markovian manner depending on both the leader and follower’s selected strategies. Although standard Stackelberg games have been utilized to improve scheduling in security domains, their deployment is often limited by requiring complete information of the follower’s utility function. In contrast, we consider scenarios where the follower’s utility function is unknown to the leader; however, it can be linearly parameterized. Our objective then is to provide an algorithm that prescribes a randomized strategy to the leader at each step of the game based on observations of how the follower responded in previous steps. We design an online learning algorithm that, with high probability, is no-regret, i.e., achieves a regret bound (when compared to the best policy in hindsight) which is sublinear in the number of timesteps; the degree of sublinearity depends on the number of features representing the follower’s utility function. The regret of the proposed learning algorithm is independent of the size of the state space and polynomial in the rest of the parameters of the game.
Selected Publication
- No-Regret Learning in Dynamic Stackelberg Games, Submitted, 2022
Online Learning for Sequential Decision Making
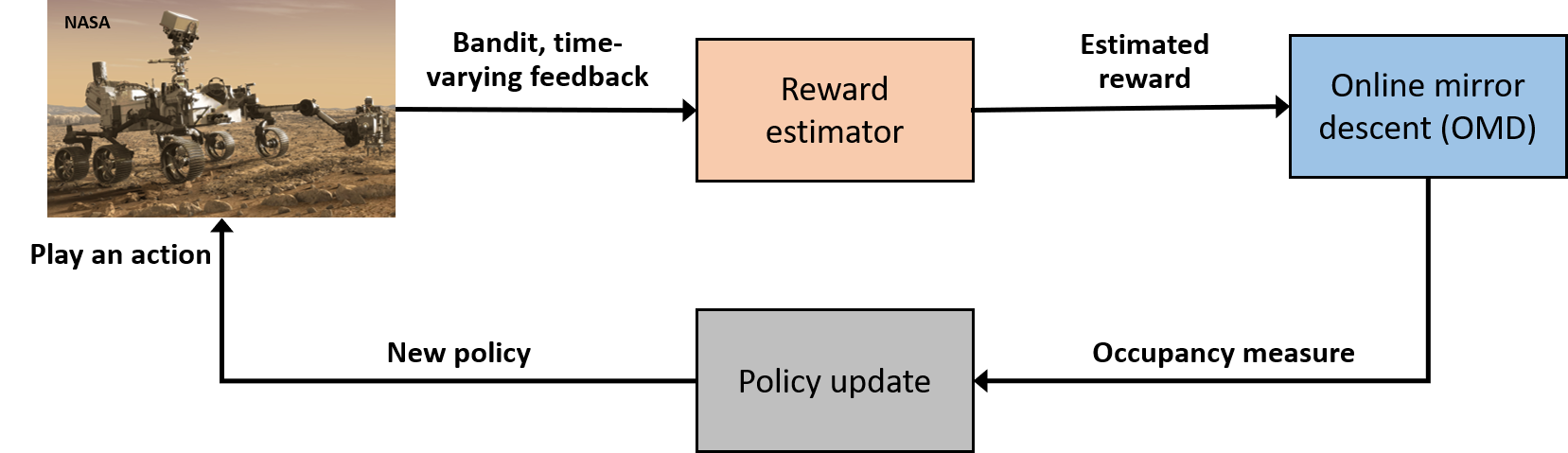
Large-scale deployment of autonomous systems in real-world applications demands control algorithms capable of handling dynamic tasks in changing environments and over extended periods. For instance, a robotic system on an exploratory mission in a new environment may have to go through a sequence of tasks whose characterization is unknown and potentially varying as the environment evolves. Furthermore, such variation may seem rather arbitrary to the system if it originates from unknown models, e.g., a human operator or a complex environment affected by multiple decision-makers. The evolution of tasks in dynamic environments requires a formalism divergent from the conventional optimal control and reinforcement learning frameworks where the task and hence its characteristic loss function (or equivalently, reward function) is either known or fixed over time. We propose learning-based online control algorithms for adversarial MDPs with bandit feedback. The algorithms compute adaptive policies that gradually change from one time to the next according to the agent’s estimate of the loss function. A central contribution of our work is to introduce an optimistically biased estimator of the loss function which encourages exploration implicitly. This optimistic bias yields a low-variance estimation, which in turn enables us to carry out a high-probability regret analysis.
Selected Publication
- No-Regret Learning with High-Probability in Adversarial Markov Decision Processes, Conference on Uncertainty in Artificial Intelligence (UAI), 2021
- Online Learning with Implicit Exploration in Episodic Markov Decision Processes, American Control Conference (ACC), 2021
Communication-Efficient Algorithms for Distributed Machine Learning and Federated Learning
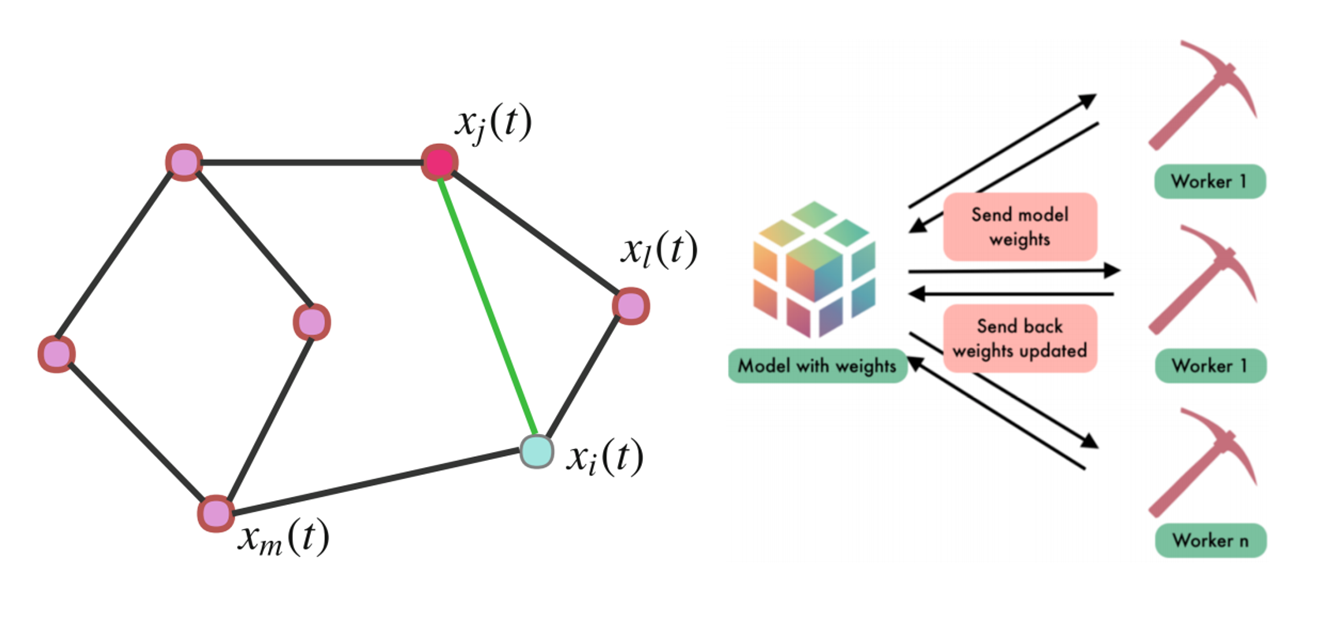
The ever-increasing computational power of modern technological devices such as mobile phones, wearable devices, and autonomous vehicles as well as the increased interest for privacy-preserving artificial intelligence motivates maintaining the locality of the data and computations. Federated learning (FL) is a new edge-computing approach that advocates training statistical models directly on remote devices by leveraging enhanced local resources on each device. In FL, the training data is stored in a large number of clients (e.g., mobile phones or sensors), and there is a central server (i.e., cloud) whose goal is to manage the training of a centralized model using the clients’ data. In contrast to the centralized learning paradigm wherein the entire data is stored in the central server, FL enables locality of data storage and model updates which in turn offers computational advantages by delegating computation to multiple clients, and further promotes the preservation of the privacy of user information. However, given the ever-increasing number of participating devices and the high degree of heterogeneity of their stored data, it is imperative to design communication-efficient and accelerated FL algorithms that can efficiently train large-scale machine learning models to high accuracy. To this end, in this project, we design algorithms for FL and (non)convex network optimization problems that are capable of finding near-optimal solutions with improved convergence rates and communication efficiency compared to the existing benchmarks.
Selected Publication
- Faster Non-Convex Federated Learning via Global and Local Momentum, UAI, 2022
- Communication-Efficient Variance-Reduced Decentralized Stochastic Optimization over Time-Varying Directed Graphs, IEEE Transactions on Automatic Control, 2022
- On the Benefits of Multiple Gossip Steps in Communication-Constrained Decentralized Optimization, IEEE Transactions on Parallel and Distributed Systems, Special Section on Parallel and Distributed Computing Techniques for AI, ML, and DL, 2022
Identification of Unknown functions and Dynamical Systems under Data Scarcity
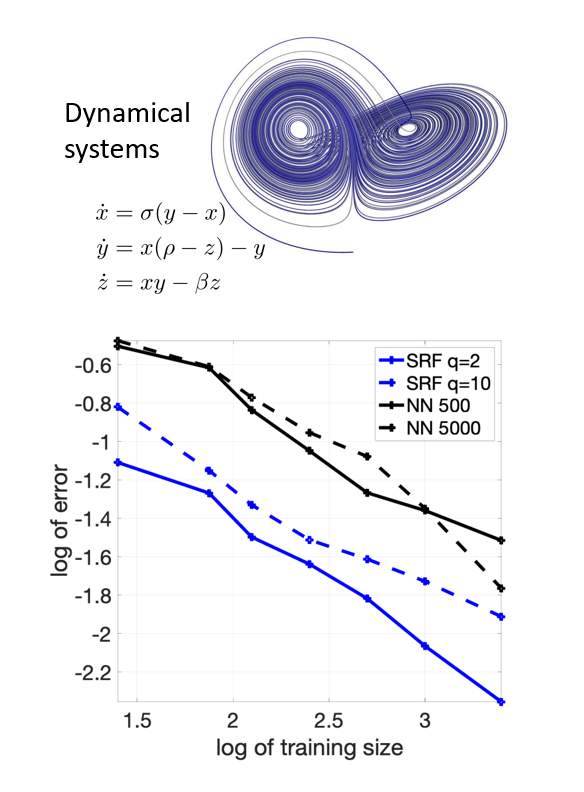
The sparsity-of-effects or Pareto principle states that most real-world systems are dominated by a small number of low-complexity interactions. This idea is at the heart of compressive sensing and sparse optimization, which computes a sparse representation for a given dataset using a large set of features. In the high-dimensional setting, neural networks can achieve high testing accuracy when there are reasonable models for the local interactions between variables. However, standard neural networks often rely on back-propagation or greedy algorithms to train the weights, which is a computationally intensive procedure. Furthermore, the trained models do not provide interpretable results, i.e., they remain black-boxes. Motivated by addressing these limitations, in this project we introduce a new framework for approximating high-dimensional functions in the case where measurements are expensive and scarce. We propose the sparse random feature method, which enhance the compressive sensing approach to allow for more flexible functional relationships between inputs and a more complex feature space. We provide uniform bounds on the approximation error for functions in a reproducing kernel Hilbert space depending on the number of samples and the distribution of features. We further show that the error bounds improve significantly for low order functions, i.e., functions that admit a decomposition to terms depending on only a few of the independent variables.
Selected Publication
- Generalization Bounds for Sparse Random Feature Expansions, Applied and Computational Harmonic Analysis,_ 2022
Submodular Information Gathering for Networked Systems
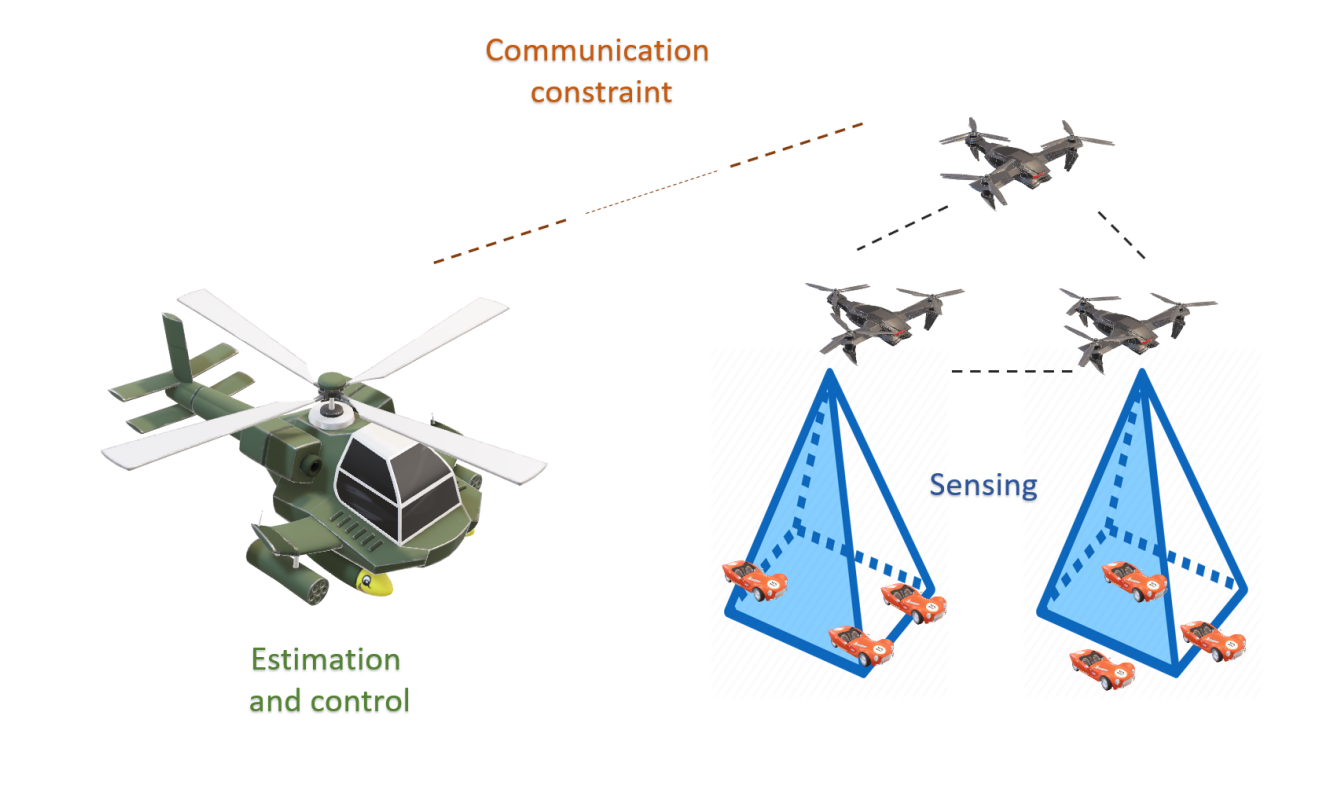
Networked autonomous systems are on a rapid path to become a ubiquitous part of the future societies. Due to the importance of such systems, in this project we studied the problem of estimating a random process from the observations collected by a networked of system of sensing agents that operate under resource constraints. When the dynamics of the process and sensor observations are described by a state-space model and the resource are unlimited, the conventional Kalman filter provides the minimum mean-square error (MMSE) estimates. However, at any given time, restrictions on the available communications bandwidth and computational capabilities and/or power impose a limitation on the number of network nodes whose observations can be used to compute the estimates. This in turn motivates the task of observation selection and information sharing to find the most informative subset of sensed information to decrease the communication burden of the system. In my first work in this project, we formulated the problem of selecting the most informative subset of the sensors in a linear observation model as a combinatorial problem of maximizing a monotone set function under a uniform matroid constraint. For the MMSE estimation criterion we showed that the maximum element-wise curvature of the objective function satisfies a certain upper-bound constraint and is, therefore, weak submodular. Since finding the optimal subset of sensed information is NP-hard, we developed an efficient randomized greedy algorithm for sensor selection and established guarantees on the estimator’s performance in this setting. Specifically, the established theoretical guarantees state that the proposed randomized greedy scheme returns a subset of sensed information that yields an estimation error that is on average within a multiplicative factor of the estimation error achieved by the optimal subset of sensed information. The proposed method is superior compared to state-of-the-art greedy and semidefinite programming relaxation methods. Recently, we extended these results to the scenarios with quadratic observation models, rather than linear models, which arise in many practical applications such as tracking objects using Unmanned Aerial Vehicles (UAVs). Finally, we have recently designed a new objective function consisting of the MMSE estimation criterion as well as a consensus-promoting regularization term with the goal of inducing a balanced performance among the sensing agents in the network.
Selected Publication
Randomized greedy sensor selection: Leveraging weak submodularity, IEEE Transactions on Automatic Control, Jan. 2021.
Submodular Observation Selection and Information Gathering for Quadratic Models, International Conference on Machine Learning (ICML), June 2019.
Clustering Temporal, Structured, and High-dimensional Data
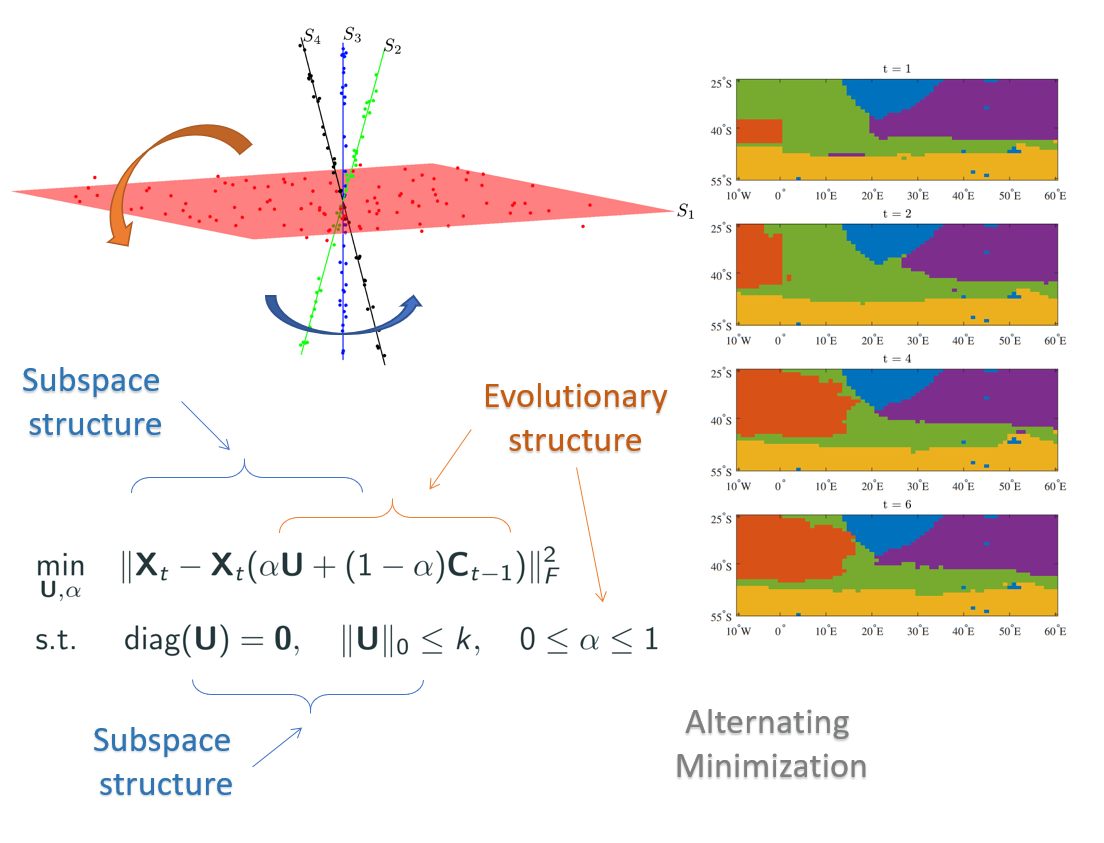
An important unsupervised learning problem deals with clustering a collection of points lying on a union of low-dimensional subspaces. Additionally, in many applications data is often acquired at multiple points in time. Exploiting the underlying temporal behavior provides more informative description and enables improved clustering accuracy. Therefore, in addition to the union of subspaces structure, there exists an underlying evolutionary structure characterizing the temporal aspect of data. Thus, it is of interest to design and investigate frameworks that exploit both union of subspaces and temporal smoothness structures to perform fast and accurate clustering, particularly in real-time applications. Given the importance of exploiting structures in clustering, we introduced Evolutionary Subspace Clustering (ESC), a method whose objective is to cluster a collection of evolving data points that lie on a union of low-dimensional evolving subspaces. To learn the parsimonious representation of the data points at each time step, we formulated a non-convex optimization framework that exploits the self-expressiveness property of the evolving data while taking into account representation from the preceding time step. To find an approximate solution to the aforementioned non-convex optimization problem, we designed a scheme based on alternating minimization that both learns the parsimonious representation as well as adaptively tunes and infers a smoothing parameter reflective of the rate of data evolution. The latter addressed a fundamental challenge in evolutionary clustering - determining if and to what extent one should consider previous clustering solutions when analyzing an evolving data collection. In two applications of real-time motion segmentation and tracking water masses near the coast of south Africa, the ESC framework outperforms state-of-the-art static subspace clustering algorithms and existing evolutionary clustering schemes in terms of accuracy while incurring a lower computational complexity and hence reduces the running time of processing the data.
Selected Publication
- Evolutionary Self-Expressive Models for Subspace Clustering, IEEE Journal of Selected Topics in Signal Processing, Special Issue on Data Science: Robust Subspace Learning and Tracking, Dec. 2018.
Sparse Tensor Decomposition for Haplotype Assembly
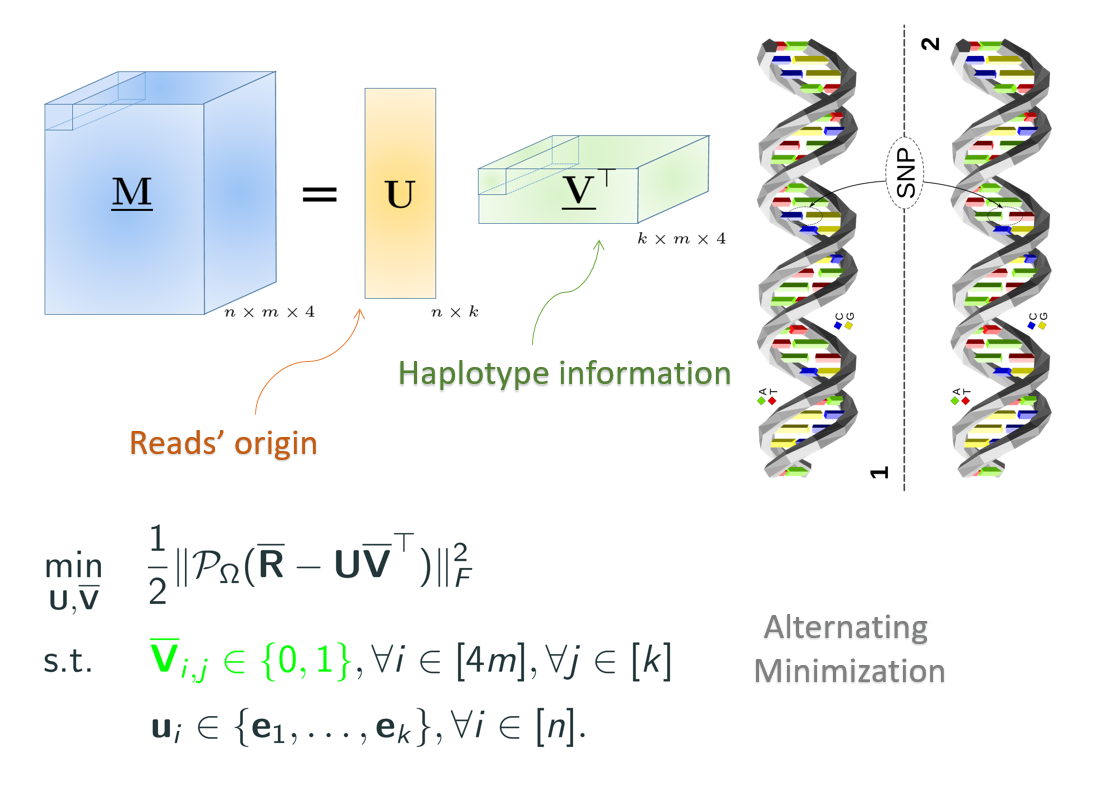
Genetic variations predispose individuals to hereditary diseases, play an important role in the development of complex diseases, and impact drug metabolism. Haplotype information which contain the full information about the DNA variations in the genome of an individual has been of great importance for studies of human diseases and effectiveness of drugs. Haplotype assembly is the task of reconstructing haplotypes of an individual from a mixture of sequenced chromosome fragments. Most of the mathematical formulations of haplotype assembly such as the minimum error correction (MEC) formulation are known to be NP-hard; the problem becomes even more challenging as the sequencing technology advances and the length of the paired-end reads and inserts increases. While the focus of existing methods for haplotype assembly has primarily been on diploid organisms, where haplotypes come in pairs, assembly of haplotypes polyploid organisms (e.g., plants and crops) is considerably more difficult. In this work we developed a unified framework for haplotype assembly of diploid and polyploid genomes. We formulated haplotype assembly from sequencing data as a sparse tensor decomposition. We cast the problem as that of decomposing a tensor having special structural constraints and missing a large fraction of its entries into a product of two factors, $\mathbf{U}$ and $\mathbf{V}$; tensor $\mathbf{V}$ reveals the haplotype information while $\mathbf{U}$ is a sparse matrix encoding the origin of the erroneous sequencing reads. We designed AltHap, an algorithm which reconstructs haplotypes of either diploid or polyploid organisms by solving this decomposition problem. AltHap exploits underlying structural properties of the factors to perform decomposition at a low computational cost. We also analyzed the convergence properties AltHap and determined bounds on the MEC scores and reconstruction rate that AltHap achieves for a given sequencing coverage and data error rate.
Selected Publication
- “Sparse Tensor Decomposition for Haplotype Assembly of Diploids and Polyploids,” BMC Genomics, Mar. 2018.
Greedy Schemes for Sparse Reconstruction and Sparse Learning
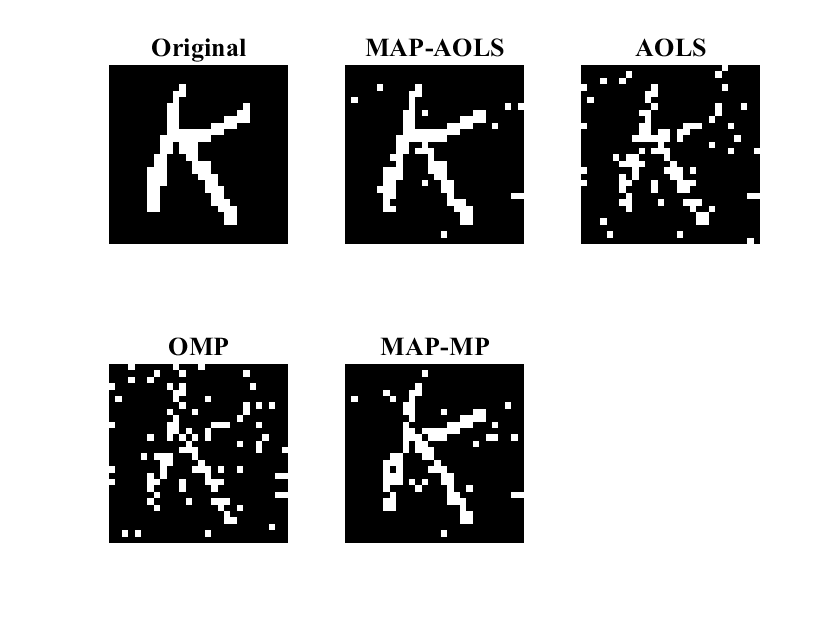
In this project, we investigated the use of iterative algorithms for the task of sparse signal reconstruction where the goal is to estimate a sparse signal from a few linear combinations of its components. This task can be readily cast as the problem of finding a sparse solution to an underdetermined system of linear equations. Sparse signal reconstruction is encountered in many practical scenarios, including compressed sensing, sparse channel estimation, and compressive DNA microarrays. We proposed an iterative greedy algorithm, called Accelerated Orthogonal Least Squares (AOLS) that efficiently utilizes a recursive relation between components of the optimal solution to the underdetermined least-squares problem with sparsity constraint. AOLS exploits the observation that columns of the measurement matrix having strong correlation with the current residual are likely to have strong correlation with residuals in subsequent iterations; therefore, AOLS selects multiple columns in each iteration and forms an overdetermined system of linear equation having a solution that is generally more accurate than the one found by the competing state-of-the-art methods. Additionally, AOLS is orders of magnitude faster than competing state-of-the-art methods and thus more suitable for high-dimensional data applications. We also theoretically analyzed the performance of the proposed algorithm and, by doing so, established lower-bounds on the probability of exact recovery of the sparse signal from its linear random measurements both with and without the presence of measurement noise. In both scenarios, we showed that AOLS scheme achieves the information theoretic lower-bound on the minimum number of measurements for exact reconstruction of the signal. Recently, we extended the AOLS method to the Bayesian setting where we exploited prior knowledge that is available on the unknown support of the signal. Additionally, we recently proposed the first algorithm for this problem that achieves the information theoretic lower-bound on the minimum number of measurements for exact reconstruction of the signal while incurring a sublinear computational complexity.
Selected Publication
“Performance-Complexity Tradeoffs in Greedy Weak Submodular Maximization with Random Sampling,” IEEE Transactions on Signal Processing, 2022.
“Accelerated Orthogonal Least-Squares for Large-Scale Sparse Reconstruction,” Digital Signal Processing, Nov. 2018.